This written version of the video tutorial was generated by an LLM from the video transcript, and supervised by me, Alejandro.
In this tutorial, we’ll explore DeepSeek V4 — a frontier-level coding model that matches or exceeds GPT-5.5 and Opus 4.7 on agentic coding tasks, at a fraction of the cost. We’ll cover benchmarks, pricing, the 1M context advantage for agents, and how to set it up with pi to build a real web app.
What is DeepSeek?
DeepSeek is a Chinese AI company that makes open-source AI models. Unlike proprietary models from OpenAI or Anthropic, DeepSeek’s models can be downloaded and run by anyone. They’ve been releasing increasingly powerful models, and V4 represents a significant leap forward from their previous V3 release.
What is DeepSeek V4?
Two models dropped with this release:
- V4-Pro — 1.6 trillion parameters, 49B active. This is the flagship model designed for complex coding tasks.
- V4-Flash — 284B parameters, 13B active. A faster, cheaper variant for simpler tasks.
Both models support 1 million tokens of context — roughly 750,000 words. To put that in perspective, the entire Lord of the Rings trilogy fits in a single prompt.
The key pitch from DeepSeek: frontier-level coding performance at a fraction of the cost of competitors.
Benchmarks: How Does It Compare?
Let’s look at the numbers across three benchmarks that matter most for coding agents.
Terminal-Bench 2.0
This benchmark tests whether a model can complete real terminal tasks.
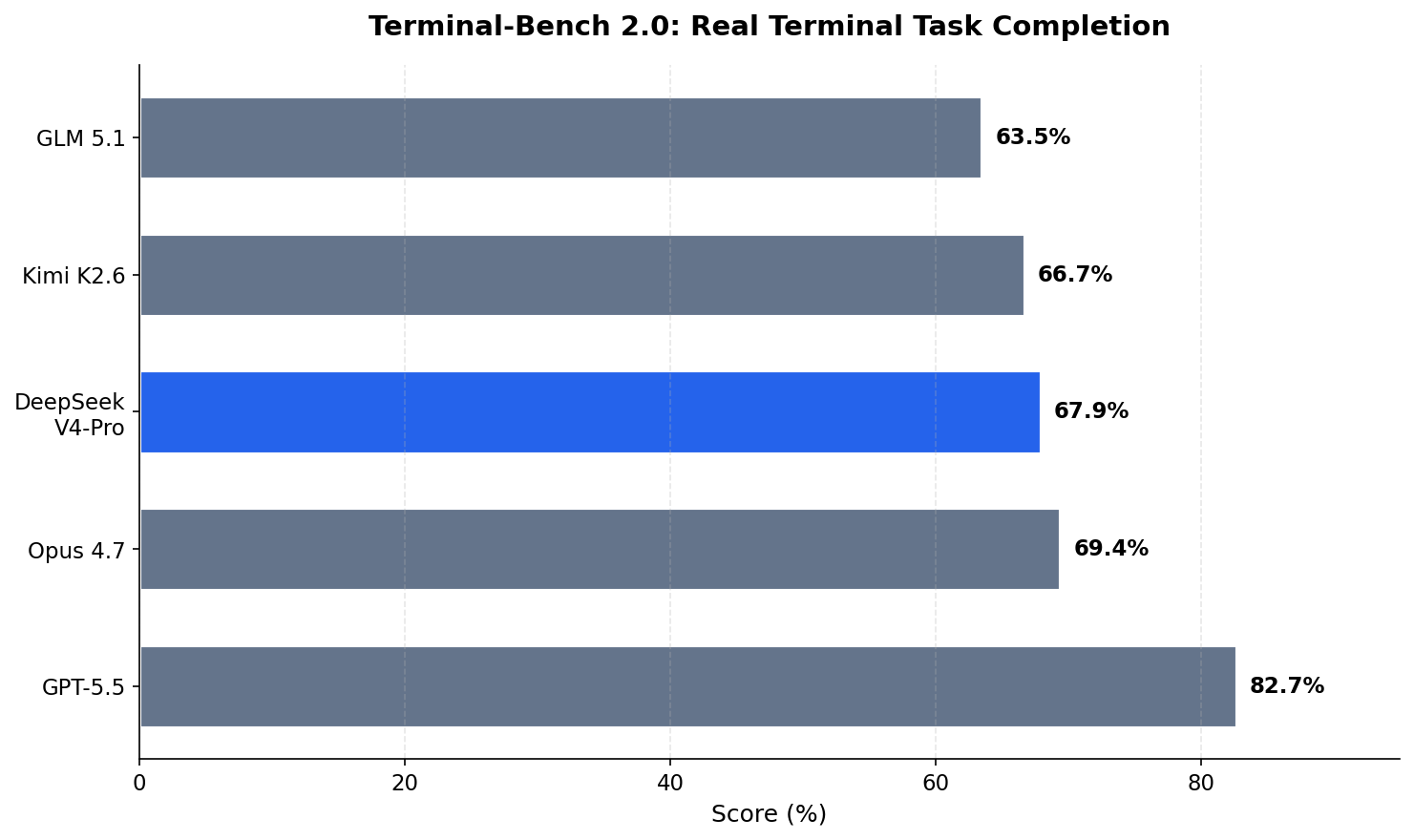
V4-Pro is not #1 here — GPT-5.5 leads. But as we’ll see in the pricing section, the cost difference makes this gap much less significant.
SWE Verified
This benchmark tests whether a model can fix real GitHub bugs — finding bugs, understanding codebases, and writing fixes.
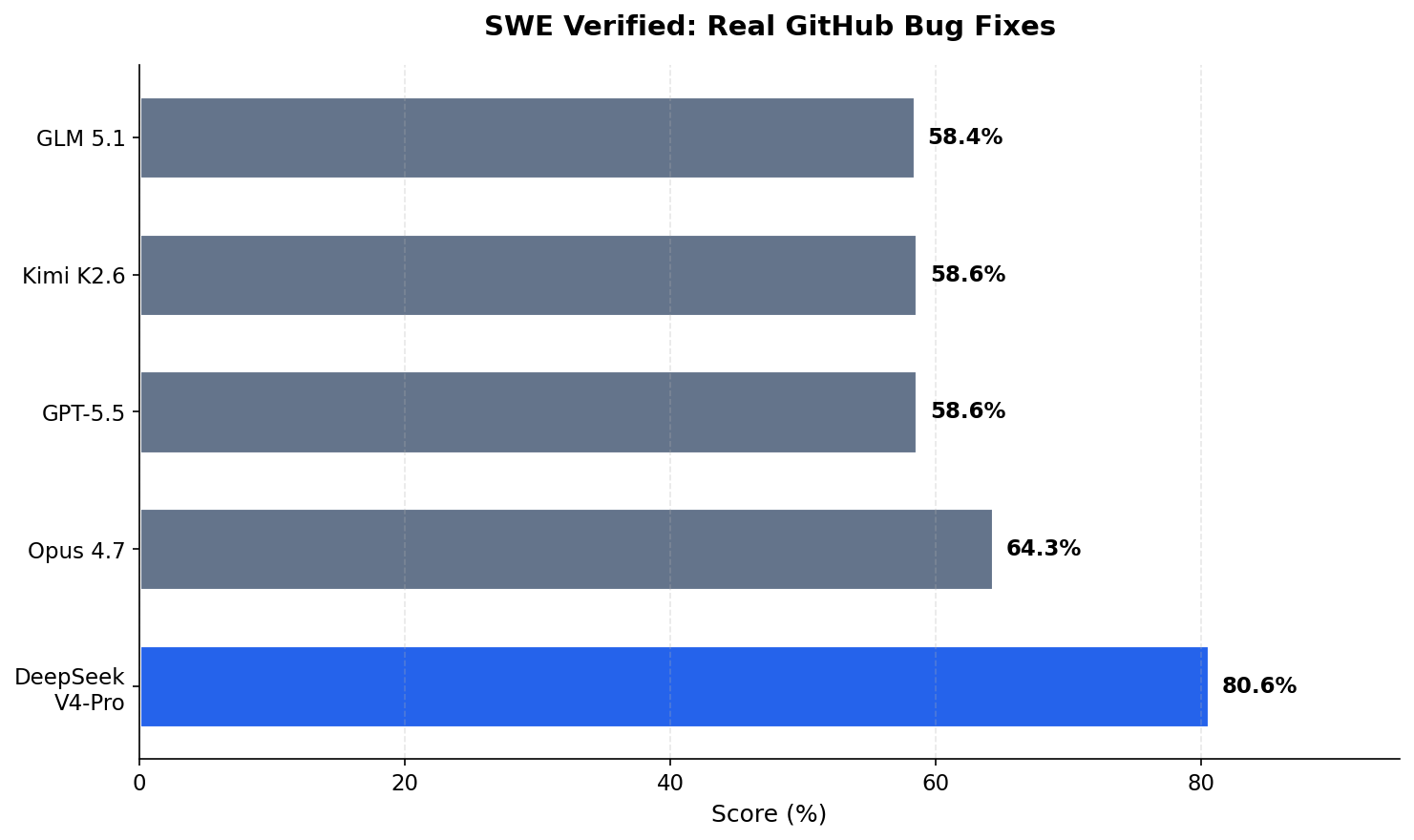
Here V4-Pro leads at 80.6%. This is the benchmark that most directly tests real coding agent work, and V4-Pro outperforms both GPT-5.5 (58.6%) and Opus 4.7 (64.3%).
MCPAtlas
This benchmark tests whether a model can use tools correctly — essential for agentic workflows.
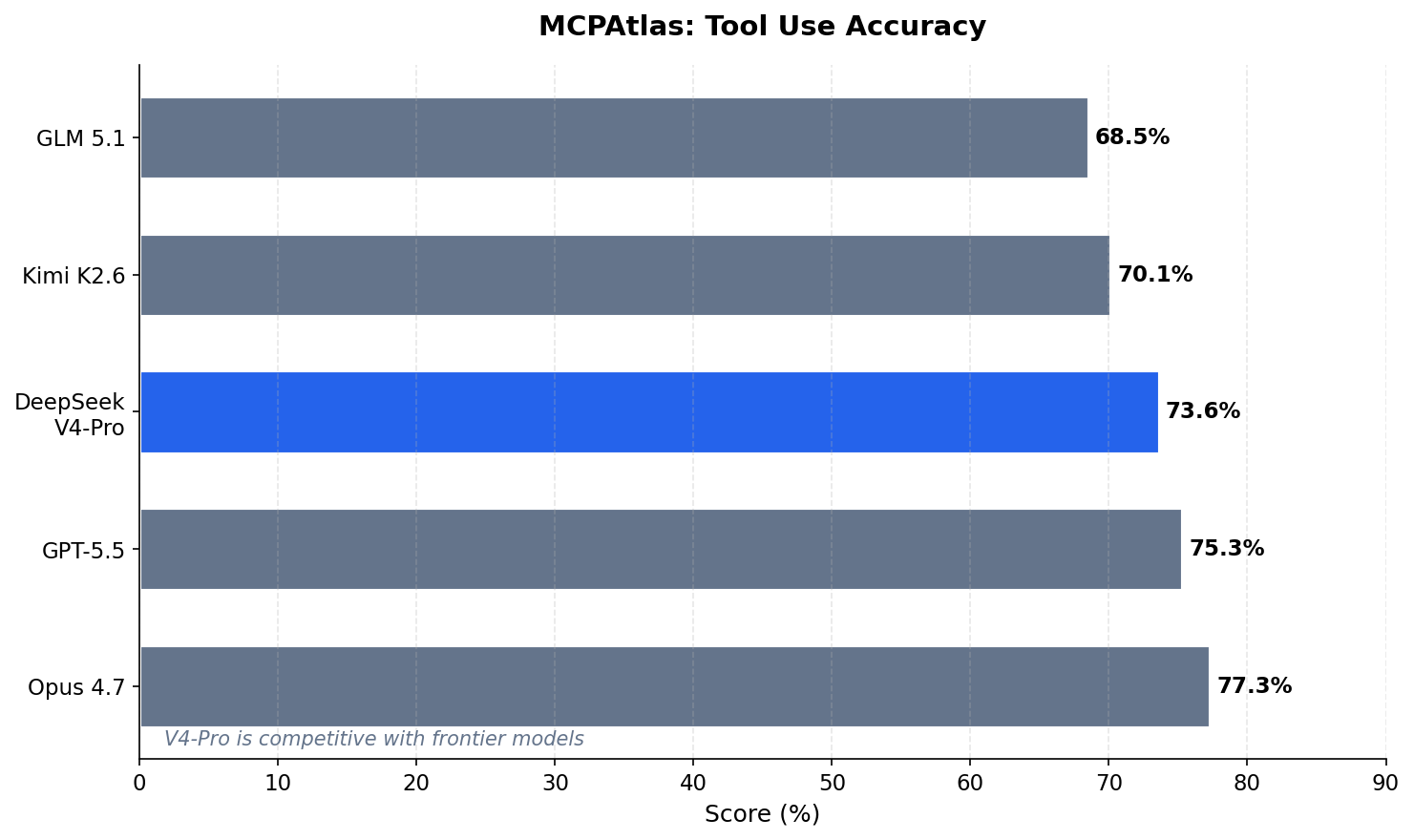
It’s a near tie. V4-Pro is right behind Opus 4.7 and GPT-5.5. Only 3.7 percentage points separate the top 3 models.
Takeaway: V4-Pro is competitive with models that cost 3-5x more. It’s not the best on every single benchmark, but it’s consistently near the top — and the pricing story makes it even more compelling.
Pricing: The Real Differentiator
This is where DeepSeek V4 gets interesting.
Input Token Costs
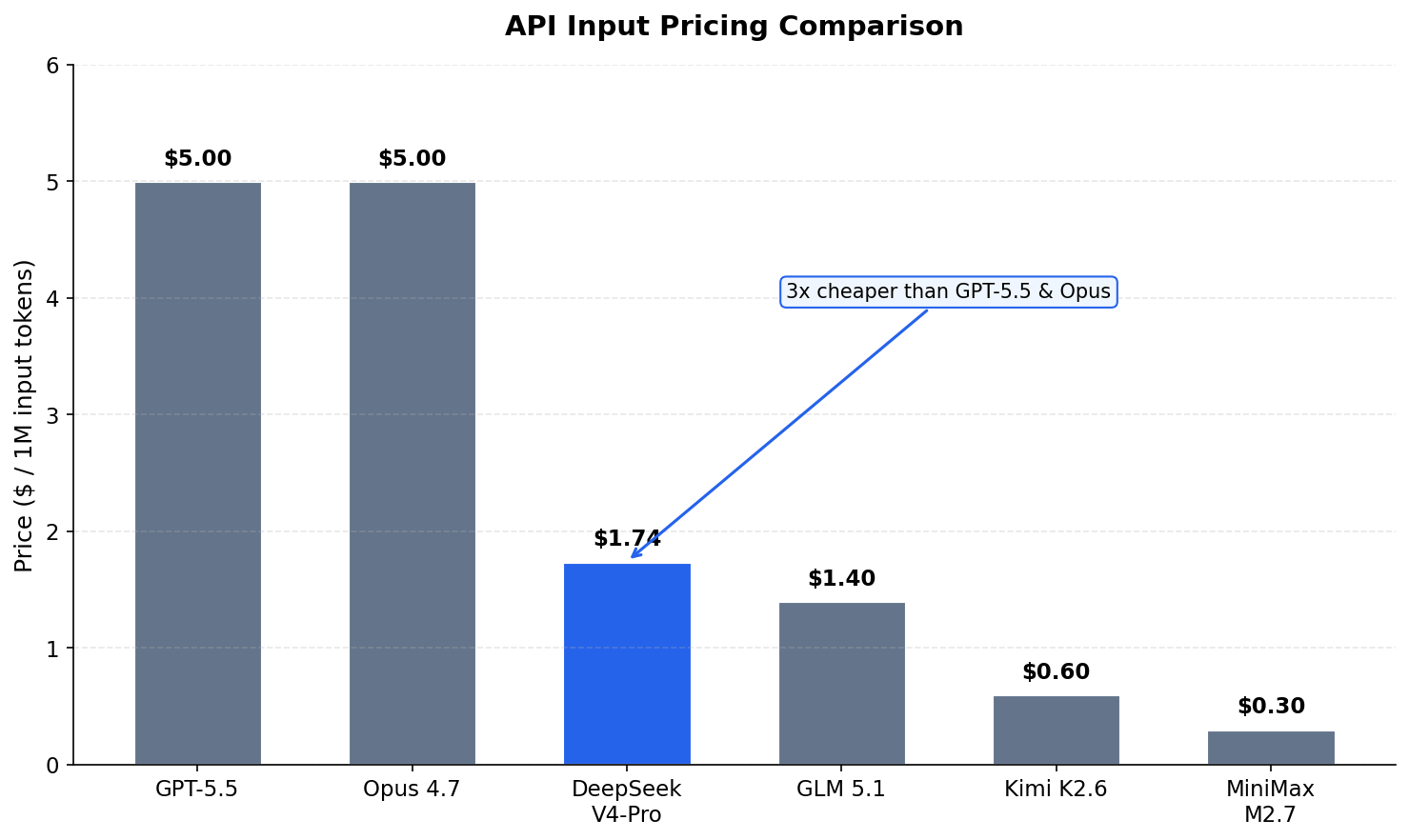
V4-Pro costs $1.74 per million input tokens. Compare that to:
- GPT-5.5: $5.00/M (3x more expensive)
- Opus 4.7: $5.00/M (3x more expensive)
Output Token Costs
Output tokens are where costs really add up during long coding sessions:
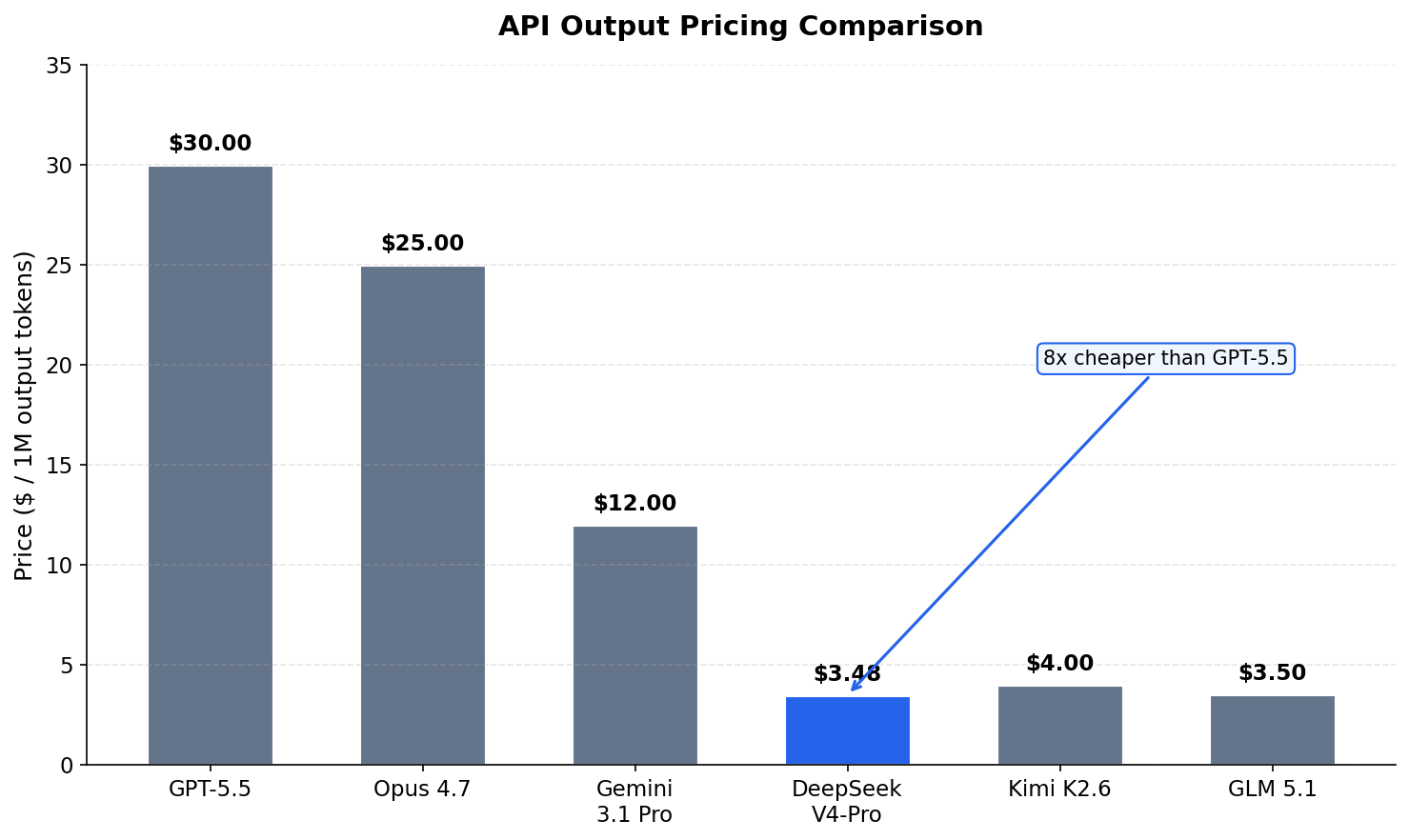
V4-Pro output is $3.48 per million tokens. GPT-5.5 is $30 per million — that’s 8x more expensive. On a long coding session where the model generates thousands of lines of code, this gap becomes massive.
Cache Hit Pricing
With cache hits (reusing previously seen tokens), the price drops to $0.028 per million input tokens — basically free.
Value Per Benchmark Point
Let’s calculate the value on SWE Verified (real bug-fixing):
- V4-Pro: $1.74 ÷ 80.6 points = ~$0.02 per point
- GPT-5.5: $5.00 ÷ 58.6 points = ~$0.09 per point
- Opus 4.7: $5.00 ÷ 64.3 points = ~$0.08 per point
V4-Pro gives you 4x more coding capability per dollar than GPT-5.5.
1 Million Token Context: Why It Matters
Most models have 128K or 200K context windows. V4 has 1M. Why does this matter for coding agents?
When an AI agent works on your code, every tool call, every file read, every terminal output gets added to the conversation. On a long task, the context fills up. The agent forgets what it did earlier. It loops or breaks.
V4’s architecture solves this differently using two types of attention:
- CSA (Compressed Self-Attention) — compresses the context 4x, then picks only the most relevant parts. Think of it like skimming a book for key paragraphs.
- HCA (Hybrid Compressed Attention) — compresses 128x, keeping a rough global picture. Think of it like reading the table of contents.
These alternate across layers. The result: V4 uses only 10% of the memory that V3.2 needed at 1M tokens. And retrieval stays at 0.59 accuracy even at the full 1M — meaning it can still find the needle in the haystack.
Interleaved Thinking
One more key feature: V4 preserves reasoning across tool calls and user turns.
Previous models would forget their chain of thought when you sent a new message mid-task. V4 keeps the full reasoning history. This is huge for agents — no more lost context between steps.
Setting Up DeepSeek V4 with pi
Let’s set up V4-Pro with pi, an open-source AI coding agent harness that talks to any LLM provider.
Install it:
npm install -g @mariozechner/pi-coding-agent
Learn more at pi.dev.
Now let’s connect Hugging Face as a provider to access DeepSeek V4. Edit ~/.pi/agent/models.json:
{
\"providers\": {
\"huggingface\": {
\"baseUrl\": \"https://router.huggingface.co/v1\",
\"api\": \"openai-completions\",
\"headers\": {
\"X-HF-Bill-To\": \"huggingface\"
},
\"models\": [
{
\"id\": \"deepseek-ai/DeepSeek-V4-Pro:novita\",
\"name\": \"DeepSeek V4 Pro (Novita)\"
}
]
}
}
}
Note: If DeepSeek V4 isn’t listed as a built-in model yet (it’s brand new), this custom config adds it via Hugging Face’s inference router. Set your Hugging Face token as the
HF_TOKENenvironment variable and you’re set.
Fire up pi:
pi
Use /model to pick DeepSeek V4 Pro from the list. Models reload live — edit models.json anytime without restarting.
That’s it. You’re running a frontier coding model for $1.74/M tokens.
Demo: Building a Code Playground
Let’s build a browser-based code playground — a mini in-browser IDE. Single HTML file with embedded CSS and JS.
The requirements:
- Layout: Three resizable editor panels side by side (HTML, CSS, JS) plus a live preview pane below
- Editors: Use CodeMirror from CDN for syntax-highlighted editing in all three panels with a dark theme
- Live preview: The preview pane shows a rendered iframe that updates in real-time as you type, debounced by ~400ms
- Persistence: Auto-save all three editor contents to localStorage on every change
- Controls toolbar: Title, Run button, Reset button, and status indicator
Watch how V4-Pro:
- Plans the approach first
- Creates the file structure
- Writes the HTML, CSS, and JavaScript
- Tests and fixes issues
Working app, built in one prompt, for pennies.
Summary
DeepSeek V4-Pro offers:
- Competitive performance with models costing 3x more
- Best value on SWE Verified — the most relevant coding benchmark
- 1M context that actually works for agents, thanks to CSA/HCA architecture
- Reasoning that persists across turns
- Fully open-source — download and run it yourself
It’s not always #1 on every benchmark. But for the price, it’s hard to beat. If you’re running coding agents daily, V4-Pro should be in your rotation.
Try it yourself — the links below will get you started.