Today I’m going to give you a very quick overview of GPT-5.5, the new release by OpenAI. No hype—just the announcement and a real comparison to open models across benchmarks and pricing to see if it’s actually worth using in your apps or coding workflows.
The Announcement
GPT-5.5 is the new model powering ChatGPT and Codex. It’s already live in those applications, and soon it’ll be available on the API for developers.
Benchmark Breakdown
OpenAI’s benchmarks show GPT-5.5 is the best model in the world. But here’s the catch—they only compare it to closed models. I compiled comparisons that include open-source models like Kimi, GLM, and Minimax.
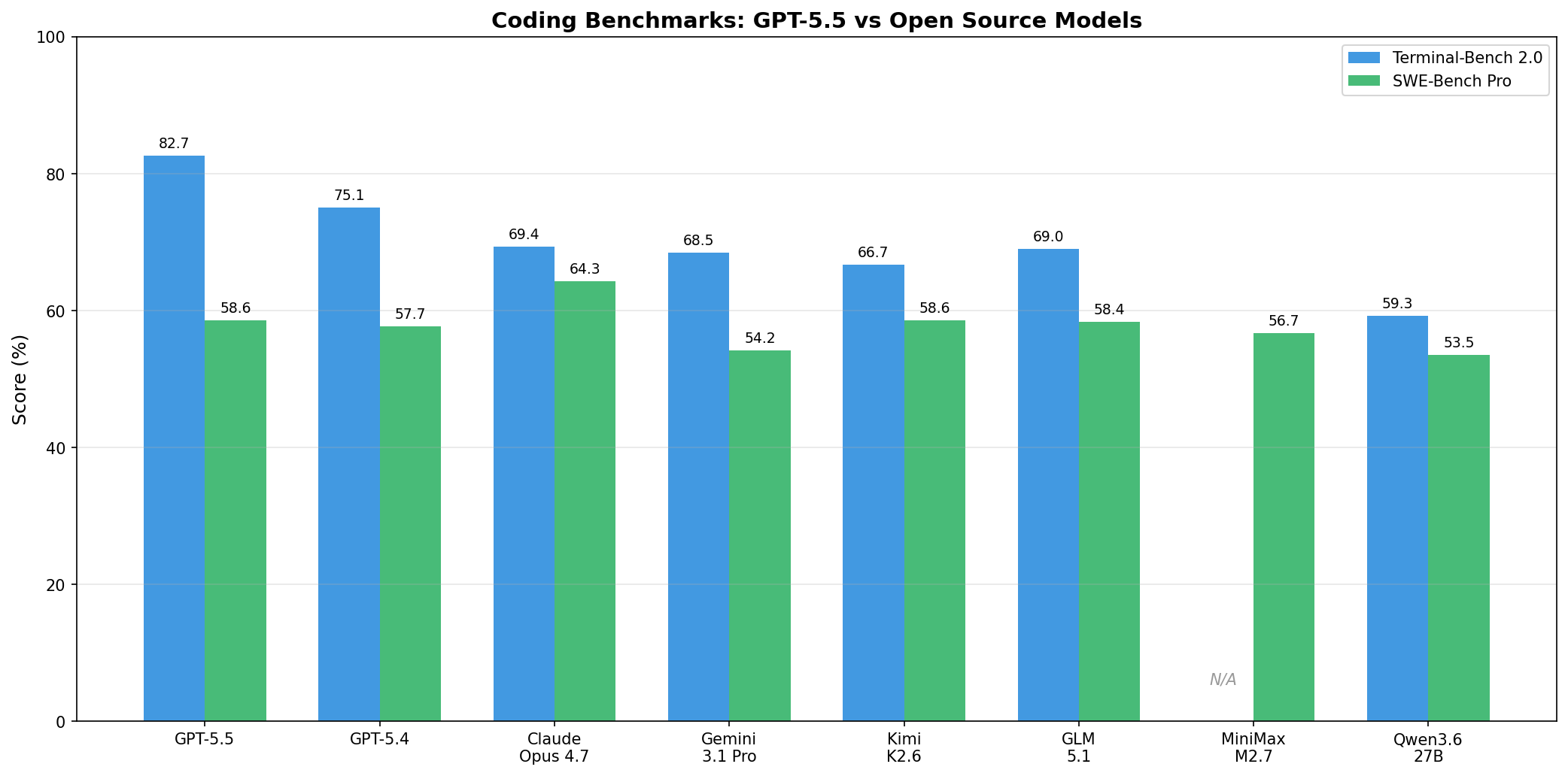
Coding Benchmarks
The most popular use case for large language models is coding. Two key benchmarks measure this:
- TerminalBench and SWE Bench Pro: These compile complicated software engineering problems. Models must edit and read multiple files to find solutions, graded by whether they found a correct solution and how good it was.
GPT-5.5 is clearly the best—higher than GPT-5.4, the previous king. But the pricing is where things get interesting.
Token Efficiency
One impressive claim: GPT-5.5 improved on GPT-5.4 while using fewer tokens. For example, GPT-5.5 reached a better score on TerminalBench using 15,000 tokens while GPT-5.4 used 18,000 tokens.
However, GPT-5.5 is twice as expensive as GPT-5.4—and it doesn’t use half the tokens. Something to keep in mind.
The Demos
OpenAI showcased GPT-5.5 building several applications:
- Space travel simulation—works pretty well
- Earthquake tracker—surprisingly solid
- Dungeon game—a fun demo
Notably, web design and UI improved significantly over GPT-5.4, which was probably its weakest point before.
The Prompting Secret
Here’s something funny: OpenAI said you don’t need to prompt GPT-5.5 specifically—it just gets you. But their demo prompts were very specific:
- Think step by step
- Take a deep breath
- Repeat the question before answering
- Imagine you’re writing this instruction for a junior developer
So yeah, specific prompting still matters.
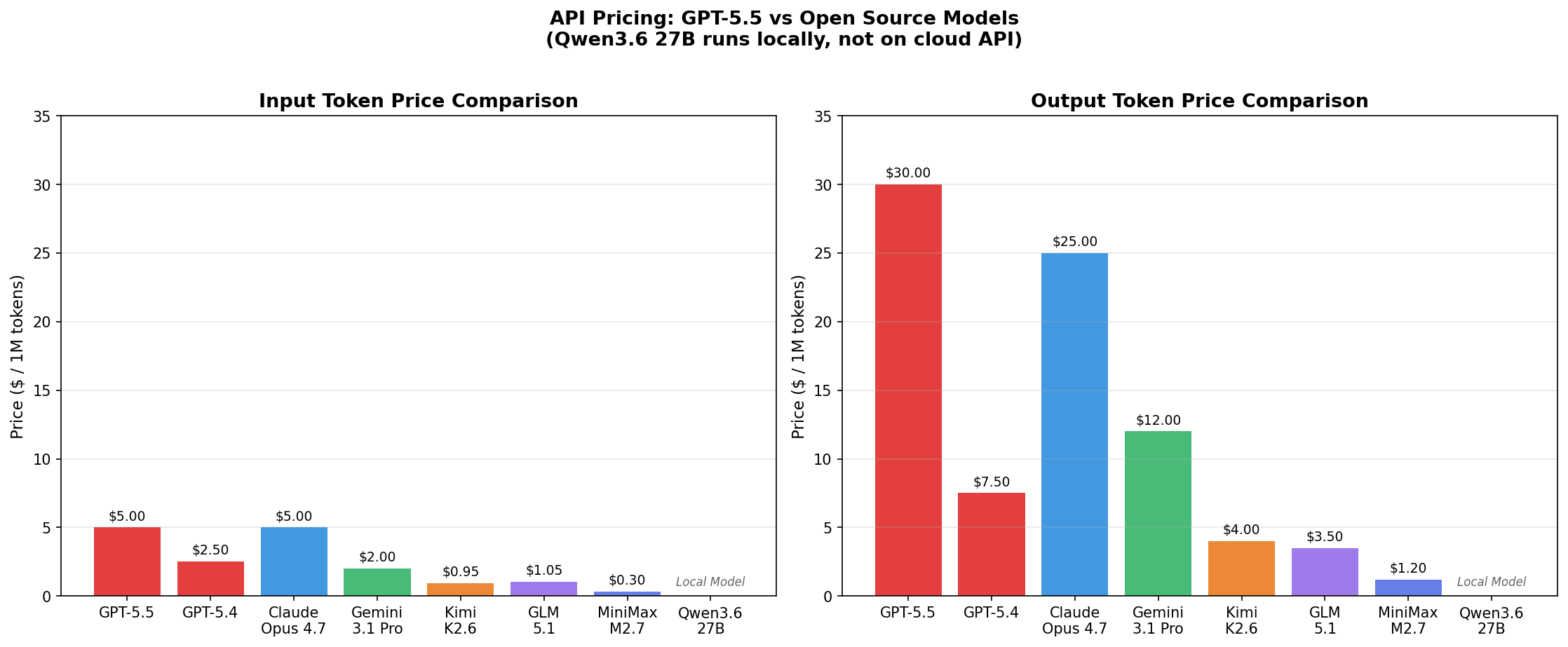
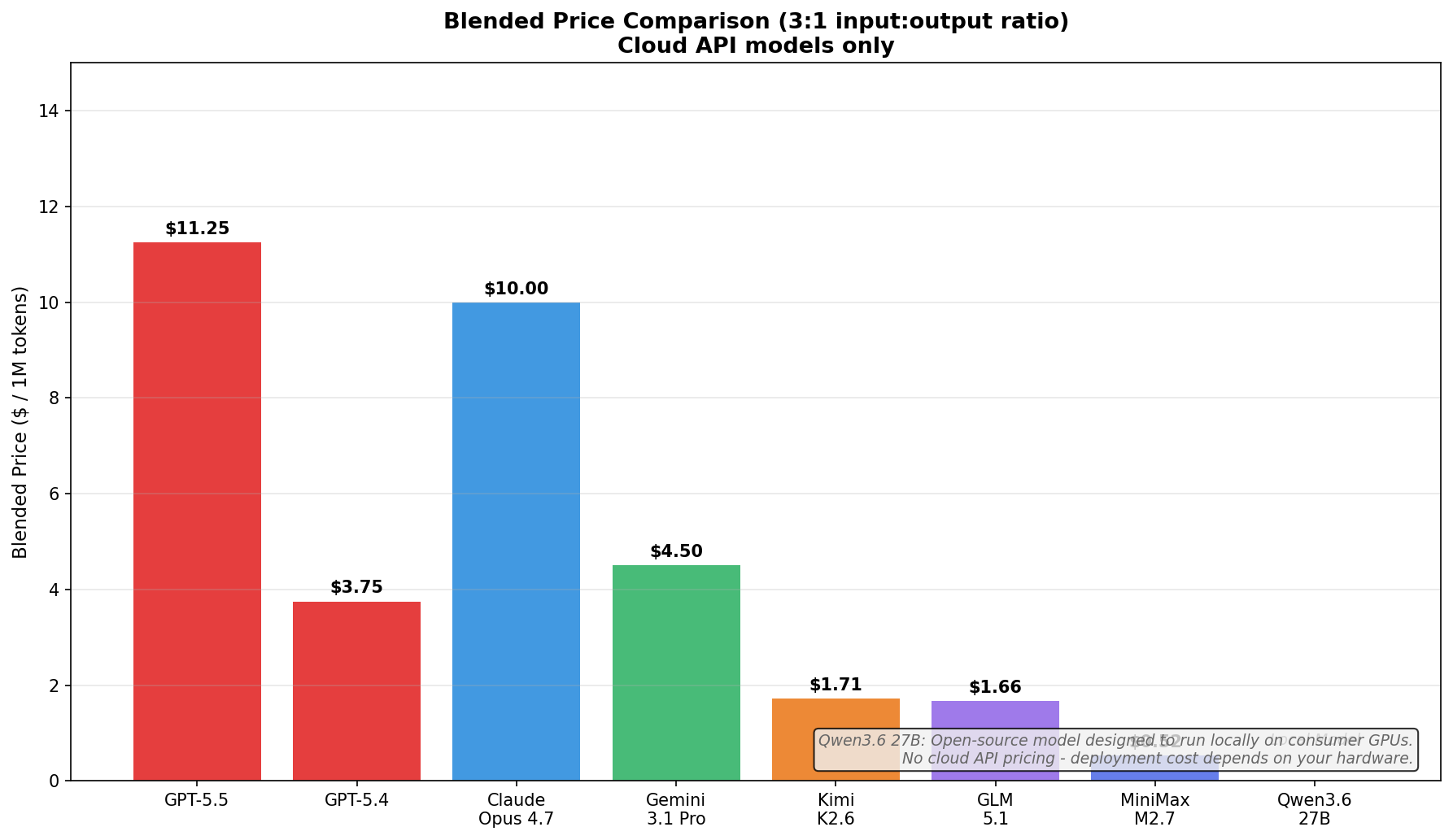
Pricing: The Reality Check
This is where it gets wild.
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| GPT-5.5 | $55 | $30 |
| GPT-5.4 | $2.50 | $15 |
| Claude Opus 4.7 | ~$15 | ~$15 |
| Gemini 3.1 Pro | ~$1 | ~$3 |
GPT-5.5 is even more expensive than Claude Opus 4.7—which is saying something.
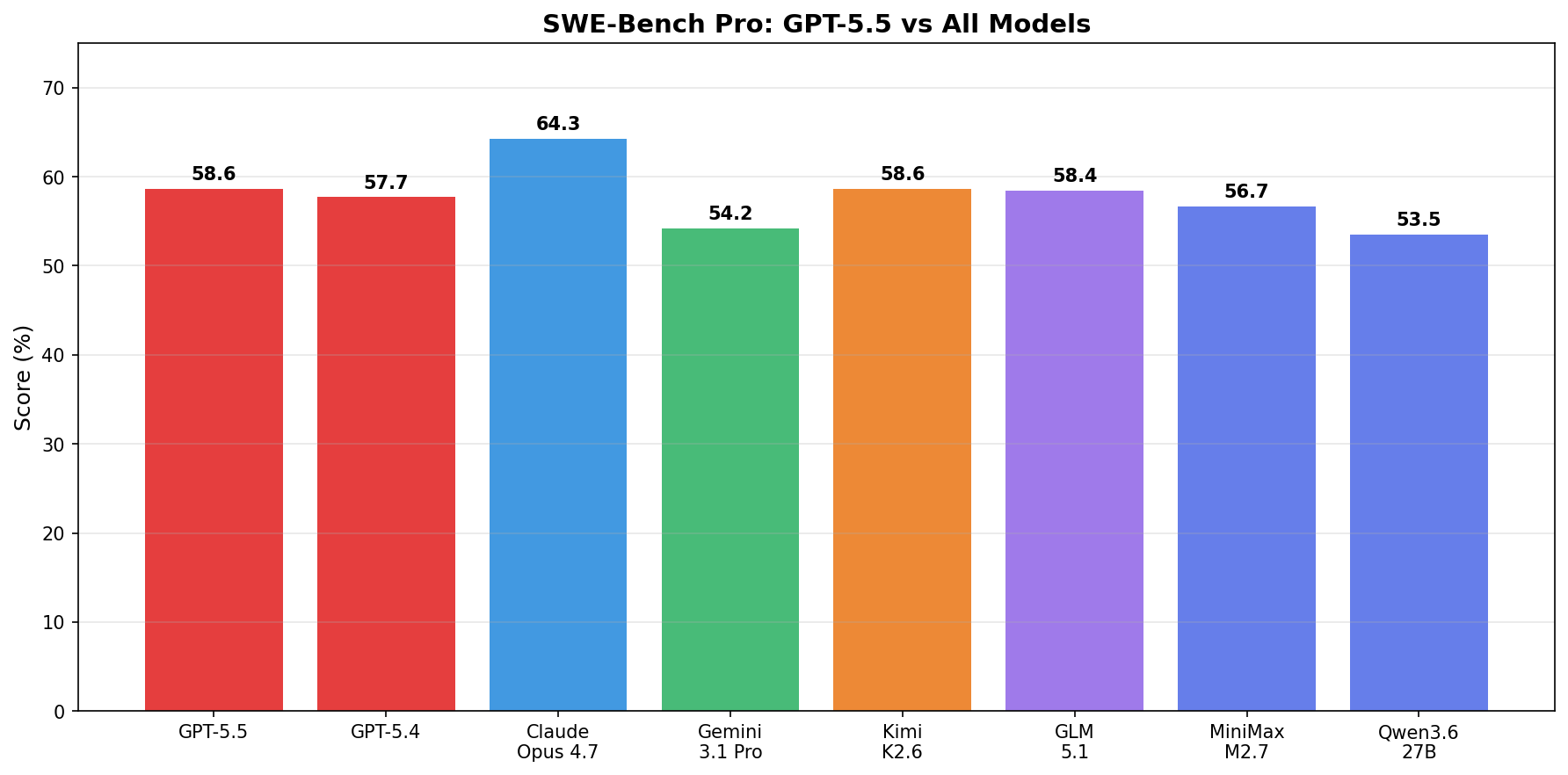
The Open Models Comparison
Here’s what really matters. Open models get comparable results at a fraction of the cost:
| Model | Output (per 1M tokens) | SWE Bench Pro Score |
|---|---|---|
| GPT-5.5 | $30 | 58.6 |
| Kimi K2.6 | $4 | Comparable |
| Minimax | $1.20 | 56.7 |
For context: Kimi K2.6 was released just this week at $4 per million tokens output—and it’s among the most expensive open models. Minimax delivers 56.7 versus GPT-5.5’s 58.6 at less than $1.50 per million tokens.
That’s incredible value.
To check these prices yourself, go to Hugging Face Inference Providers, select your model, and compare. For example, with Novita:
- Kimi: $0.95 input / $4 output per million tokens
- Minimax: $0.30 input / $1.20 output per million tokens
Compare that to GPT-5.5 at $55 input / $30 output.
Open models for the win.
Demo: Building a Landing Page with Codex
I tested GPT-5.5 through Codex (available at developers.openai.com/codex/app). I set it to extra high intelligence and asked it to create a beautiful landing page for GPT Rosalind, being creative with recent web design trends.
It thought for about seven minutes and finished the entire page—creating an index.html, styles.css, and script.js.
The result? Much better than what I’m used to from GPT models. Honestly, incredible.
Yes, it’s a simple task, but if you’ve followed the channel, you know these models are already great at backend tasks. The only weak link was always frontend design—and GPT-5.5 is finally doing a great job here.
Conclusion
GPT-5.5 is genuinely the best model in the world by the benchmarks. But with pricing that’s 10-20x higher than comparable open models, you need to decide if those marginal benchmark improvements justify the cost.
For many use cases, Kimi or Minimax will give you 95% of the results at 5% of the price.