In this lesson, we will go through an introduction of LlamaIndex. We will see what you can do with it, how it deals with RAG and its main components. We will then implement a RAG pipeline with their famous 5-liner, which allows you to chat with your data in 5 lines of code. This tutorial is based on the original LlamaIndex documentation.
What is LlamaIndex?
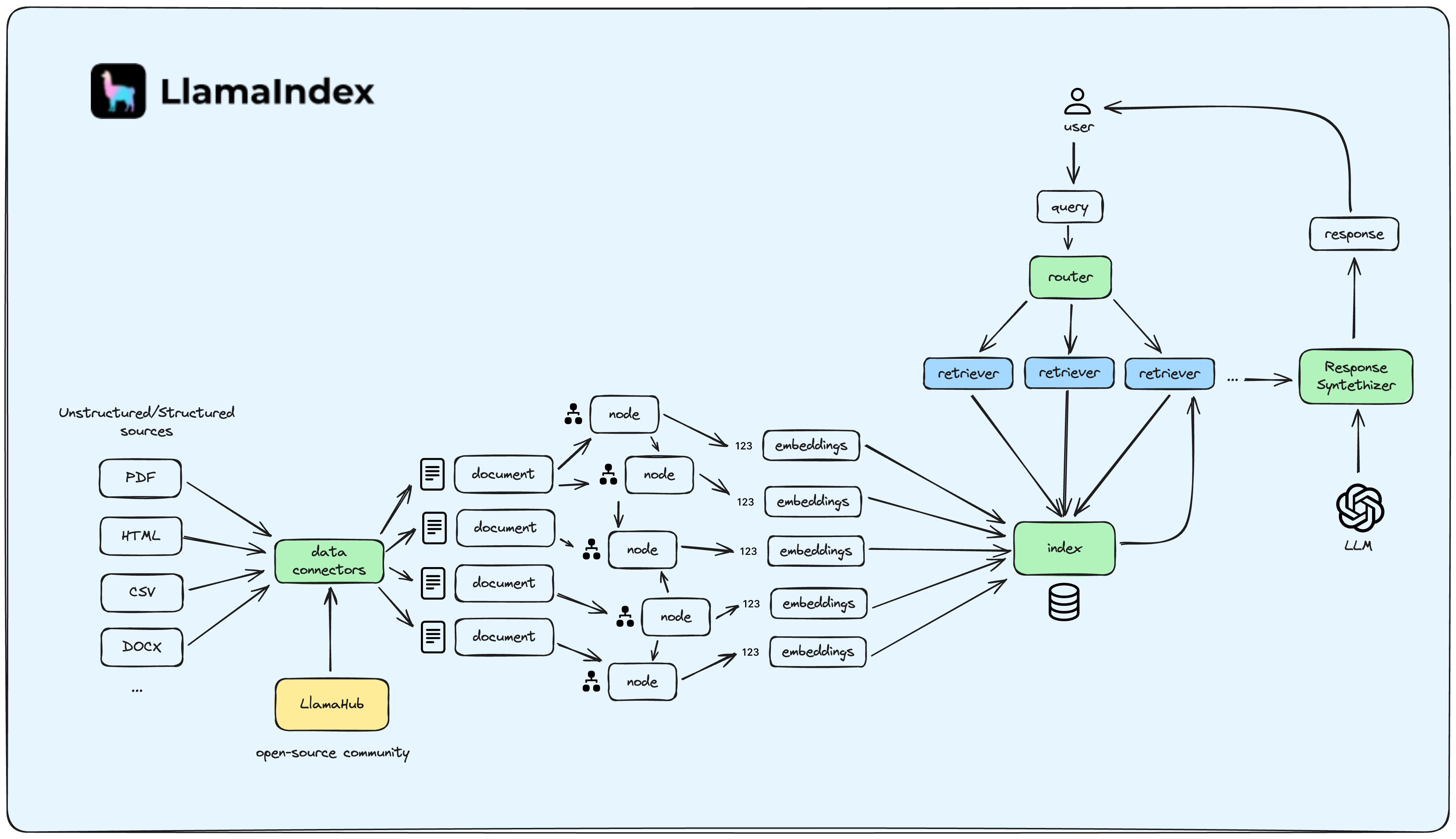
LlamaIndex is a Python library that allows you to build a search engine for your documents. It is designed to be simple to use and easy to integrate with your existing code.
Installation and Setup
To install LlamaIndex, you can use pip:
%pip install -Uq llama-index
LlamaIndex uses OpenAI’s models by default (both for embeddings and LLM), so you will need an API key to use it. You can get an API key by signing up for an account on the OpenAI website. Once you have an API key, you can set it as an environment variable in your code:
import getpass
import os
os.environ['OPENAI_API_KEY'] = getpass.getpass("OpenAI API Key: ")
Getting Started
To get started with LlamaIndex, you first need to create a VectorStoreIndex object. This object will store the documents you want to search through. You can create a VectorStoreIndex object from a list of documents.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What is the first article?")
print(response)
Note that we are using SimpleDirectoryReader. This reader will load any file it finds in a given directory. It is capable of ingesting the following formats:
- .csv - comma-separated values
- .docx - Microsoft Word
- .epub - EPUB ebook format
- .hwp - Hangul Word Processor
- .ipynb - Jupyter Notebook
- .jpeg, .jpg - JPEG image
- .mbox - MBOX email archive
- .md - Markdown
- .mp3, .mp4 - audio and video
- .pdf - Portable Document Format
- .png - Portable Network Graphics
- .ppt, .pptm, .pptx - Microsoft PowerPoint
For more information on SimpleDirectoryReader, you can visit the official documentation.
Persisting the Index
You can persist the index to disk so that you can load it later without having to re-index your documents. VectorStoreIndex has a persist method that allows you to save the index to disk. You can then load the index from disk using the load_index_from_storage function. Here is an example:
import os.path
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
# check if storage already exists
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# Either way we can now query the index
query_engine = index.as_query_engine()
response = query_engine.query("What is the third article about?")
print(response)
LlamaParse
We can also load our documents using LlamaIndex’s API, which automates the extraction of more complicated documents:
# LlamaParse is async-first, so we need to run this line of code if you are working on a notebook
import nest_asyncio
nest_asyncio.apply()
Set up your API key:
import getpass
import os
os.environ["LLAMA_CLOUD_API_KEY"] = getpass.getpass()
Now you can use LlamaParse to load your documents:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_parse import LlamaParse
documents = LlamaParse(result_type="text").load_data("./your-file.whatever")
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What is the first article?")
print(response)
Conclusion
In this lesson, we learned about LlamaIndex, a Python library that allows you to build a search engine for your documents. We saw how to install and set up LlamaIndex, how to get started with it, and how to persist the index to disk. We also learned about LlamaParse, which automates the extraction of more complicated documents. In the next lesson, we will see how to use LlamaIndex to build a RAG pipeline.